How Do People Search Engines Work?
6 Revisions

Ever tried searching for someone on a people search engine? Simply enter the clue you have — whether it’s a name, a phone number, or an address — into the search box, and within seconds, you may receive a detailed report on the potential person you’re looking for. The process is just like using Google, right? But unlike general search engines, people search sites focus specifically on personal information, providing more targeted results about the individual you’re searching for.
So, how do they achieve this? In this article, we’ll explore the inner workings of some typical people search engines and the technologies behind them to help you understand how these platforms can find someone or gather related information about them. We’ll take you through the “journey of data”, starting with how people search engines collect information, then how they prepare and process it, and finally, how they match it to deliver an insightful report.
Table of contents
1. How people search engines collect data
People search engines collect publicly available data and some authorized data from exclusive sources including, but not limited to, public records from the Internet, social media data, governmental sources and commercial sources, etc.
We could conclude, based on the interviews with insiders, the documents of authority investigations, and the patent documents they submitted, etc., that people search engines collect data mainly in two ways: one is to scour raw data through first-hand approaches, while the other is to acquire mature and pre-processed datasets.
![]() Read more: Sources of Data: Where do people search sites get their data
Read more: Sources of Data: Where do people search sites get their data
First-hand approaches to gather data
According to statistics, 96.9% of the population in Northern America is now actively online1, which is probably the biggest free ocean of public data for people search companies to explore. The large amount of readily available data makes it easy to gather massive first-hand data directly.
In most cases, first-hand data gathering comes in two parts: web crawling and web scraping. Web crawling uses computer programs (aka web crawlers) to find and index web pages that contain useful personal information. Then the scraper (also computer programs) extracts the raw data from the marked pages and converts it into the same format.
For example, in the patent applied by PeekYou, a famous people search brand, the company showcases their technology of scraping identifiers from URLs and hyperlinks — like for an about page (http://johndoe.com/aboutus.html), the crawler will scan the text on the page and look for essential information such as the name, education, affiliated institutions, locations, and finally save them for later comparison. It’s worth noting that people search engines don’t just grab text; they also gather information from images. When they scan a page and capture a daily photo of someone, their scrapers can extract and preserve the metadata from the image, such as the possible geolocation, profession, etc., for further data matching.

Before there was Internet, however, the most common approach to get first-hand data was to hire private investigators and conduct in-depth research on the target people2. In fact, some people search sites still offer similar services to their VIP clientele — For instance, you may hire a search specialist at the people search site Social Catfish to dig up information on-demand3. As the business grows and the investigation experiences accumulate, some popular people search sites, like White Pages and Spokeo, have also developed their stable and exclusive sources of information, which give them a unique edge in rare data collection on the market.
Apart from these approaches, government agencies are also a first-hand data source people search sites would cooperate with directly. There is news of state governments opening specific portals to certain data brokers (companies that buy and sell data)4, allowing them to make information requests and access the public records in batches, such as traffic records, properties, bankruptcies, and so on. In return, government agencies would use these services for marketing, ID verification, and people search purposes5.
Off-the-shelf Datasets
People search sites don’t always rely on their own network resources and technology to get data. There’s another source that acts as an important and promising supplement – cooperating with third parties who manage massive data in certain fields.
And here’s the first potential data source. You may find news revealing telephone companies, car dealers, social media apps, etc. trade user data with data brokers6. These companies are able to collect first-party user data, from basic to comprehensive. And they tend to share these data with third parties through cookies (a piece of data websites stored on your device to remember info about you), or in some cases, they just sell the entire datasets, allowing others to develop databases and portals for their marketing purposes.
Then we have another more important source. There are also companies built for the sole purpose of data trading. These data brokers aggregate data that is proprietary or publicly available, organize it and sell it to others — which are mainly businesses in the same data industry. People search sites are often considered one of them, only they provide services mostly to individuals.

In the modern day, upstream data providers like Bright Data7 may offer not only a simple dataset that’s huge and updatable but also customized services for specific pre-processing needs. People search sites then pull the data from their upstream providers, usually through API (Application Programming Interface), a programmatic access point to a database. This way they can access multiple updatable and targeted sources on the fly, and without the overhead of data management.
According to FTC’s research report on data brokers, “the… data brokers studied obtain most of their data from other data brokers rather than directly from an original source”5. So we could infer that it’s a cost-effective choice for people search sites to purchase the “fuel” directly and invest more in the technology of “how to run”, namely how to match the data to construct a helping report.
2. How people search engines pre-process data
People search tools gather data from a wide variety of sources and in different ways, which means the data collected often differs significantly as they could be in different formats, terms, and categories. For the data to be used effectively, people search sites will need to do some processing about it.
This process is mainly made of two parts: cleaning and segmentation8.
- Data cleaning: Restructure the raw data into a unified format that people search engines can identify (like using dashes in phone numbers or removing dots in date of birth info), delete incomplete or unrecognizable data, and correct spelling mistakes.
- Data segmentation: People search sites use data management platforms (DMPs) to filter data and build categories. In this process, data will be segmented based on attributes like industry, company size, revenue, and job titles.
Many upstream data brokers probably take on part of the data processing job, especially those who provide customized datasets. After all, there’s a vigorous subsidiary data market. And since the upstream providers handle data to their own standards, sometimes you may see duplicate information in the same people search report, only with a slightly different description or category. For example, the same drunk driving incident may be listed twice in the same report, with one entry labeled “DUI” and another “Drunk Driving”, even though both refer to the same event.
3. How people search engines match data
Now, with the vast volume of data at hand, people search engines face a real challenge: how to identify and piece together bits of data about the same person from a massive ocean of random information, and then compile them into comprehensive profiles. The magic behind this process is called data matching, and it’s where the true strength of people search engines lies.
Data matching and its important role
Data matching is like a digital puzzle. It’s a technology that uses clever algorithms and techniques to search for patterns, similarities, and relationships within the vast range of available data. Specifically, it works by analyzing and comparing various data points, such as names, addresses, dates of birth, and other relevant identifiers, across multiple data sources to recognize connections.
For example, if dataset A includes someone’s name, phone number, and email address, and dataset B includes another one’s name, phone number, and address, then the identical name and phone number might suggest that the two datasets refer to the same person. Furthermore, when data shows that two persons share the same last name, like Mary James and Michael James, and come with the same house address, data-matching algorithms might group them as a family.
When data matching is done well, it can uncover a lot of information. Imagine it successfully pairs someone’s online username with their real name from various data sources; their true identity can come to light. But in practice, how do people search engines manage to identify relevant information? How can they recognize social relationships between individuals? And why do they sometimes make mistakes? All the answers can be found in their data-matching designs, which will be covered in the sections below.
The secrecy of data matching
Before we delve into the specifics of data-matching designs, it’s necessary to understand that these techniques are usually kept confidential by people search engines, much like how Coca-Cola guards its secret formula. After all, this knowledge determines their competitive edge in the industry. In an attempt to unveil these secrets, we turned to various sources of information. We dug into technology patents, reports, news, and interviews of experts and practitioners in the industry to shed light on this process. In the meantime, we also tested over 10 people search products to verify our findings and assumptions.
What we do know comes from two main sources: the technical principles outlined in patents submitted by people search companies, and our firsthand experience and deductions backed by extensive research. In particular, we looked at patents from PeekYou and Intelius, two long-standing people search engines, to understand the basics and real-world applications of data matching.
Linking virtual and true identities
One of the aspects about people search engines that intrigues us the most, and a major reason why people use these services, is their ability to uncover real identities behind virtual personas. Let’s say you want to find out who is behind a username or phone number, people search engines can help with that using data matching. For that, PeekYou introduced a method back in 2009 that can match people’s real names with their online pseudonyms9. It efficiently collects, identifies, and integrates scattered personal data about a specific individual into comprehensive profiles.
The technology uses algorithms to compare newly indexed data from public sources with existing personal profiles and identify matches, as shown below. This involves a detailed comparison of data points including last names, first names, addresses, dates of birth, email addresses, and phone numbers (sorted by importance). If a match is found, the new data is merged with the existing profile; otherwise, a new profile is created. Over time, this builds up detailed profiles.
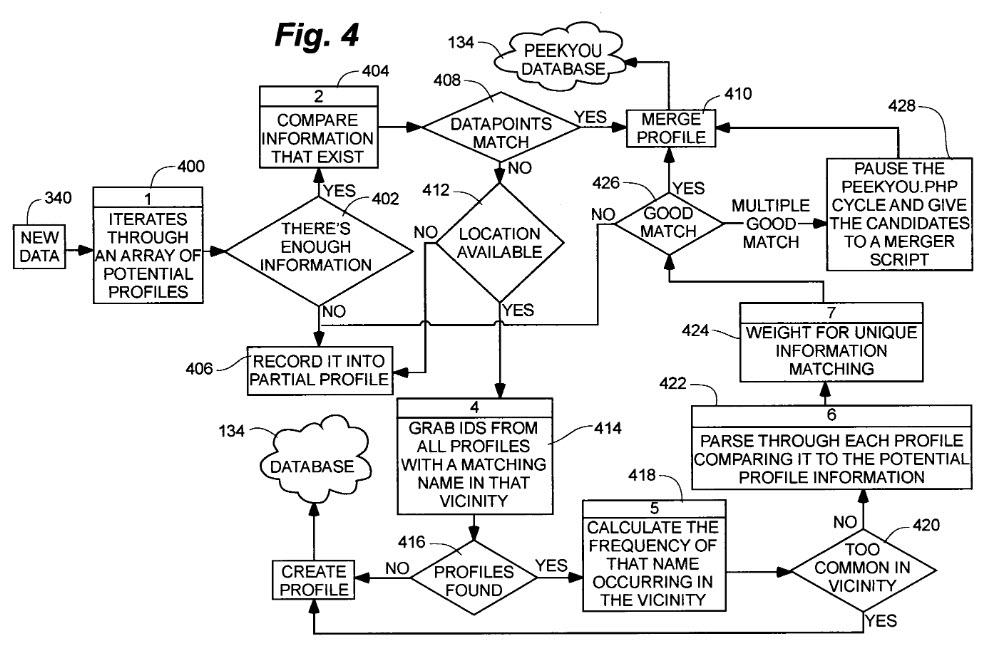
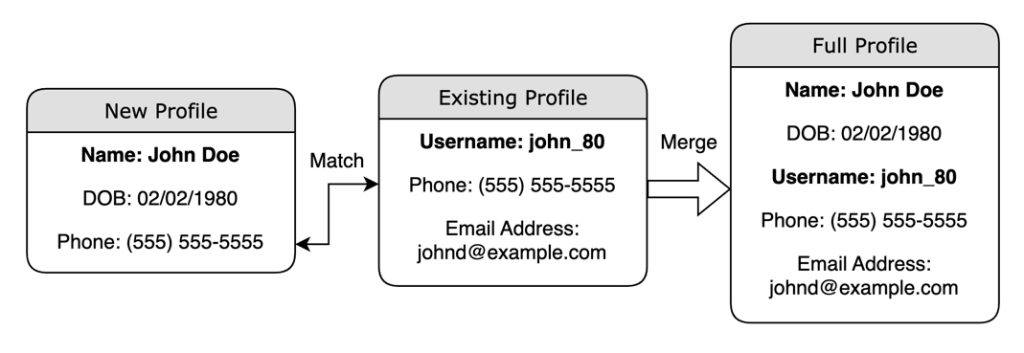
How does this help uncover a person’s real identity from just a username or phone number? Let’s break it down with a simple example. Suppose the system has received a new dataset about someone named John Doe, which includes his name, date of birth, and phone number. This data is then matched with an existing profile that already contains his username, phone number, and email address. By merging these datasets, the system creates a comprehensive profile that links both his real name and his username, as shown below. That’s how the potential identities behind virtual personas like usernames, phone numbers, and email addresses get revealed.
Recognizing familial relationships
In addition to the way people search engines bridge the gap between real identities and the online presence of individuals, we’re also curious about how they can recognize familial and social relationships among individuals. Imagine searching for a long-lost family member: you might wonder how machines can understand and accomplish such a subtle task. But fundamentally, it’s still a process of data matching and comparison.
And one method people search engines use to identify potential familial relationships is by looking for the same last names and addresses. The details can be found in the patent submitted by Intelius, a well-known people search site that specializes in background checks.
Intelius groups personal information from public sources to create household units, which helps connect individuals with their families and makes search results more relevant10. Essentially, it extracts key data points like names, dates of birth, and addresses from each public dataset obtained and refines them for further analysis. Records that share the same last name and street address are then considered relatives and are grouped together in the reports shown to users.
The whole process is shown below.
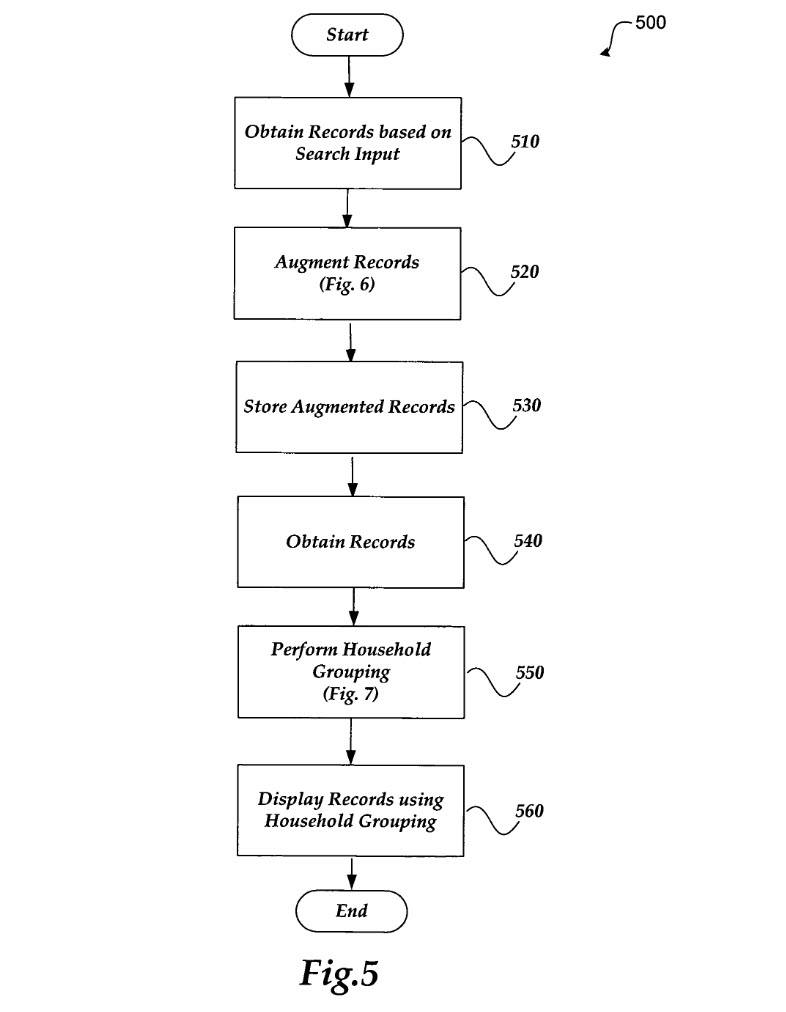
You’ve probably noticed that this method uses shared last names and addresses to identify potential family members. It’s a simple yet straightforward description of familial relationships, allowing machines to quickly understand and process data. Our hands-on tests on several people search platforms confirmed this as well. For example, when searching on Intelius, we found that individuals sharing the same last name and address as the person being searched were consistently included in the possible relative list. This pattern repeats across other platforms like BeenVerified, suggesting that other people search engines might also consider these two as important factors when they match data and recognize possible family members.
While this method works well in many cases, it has its limitations. One user shared a funny story about searching for himself on Spokeo, another people search engine. When he was doing the search, an online profile he created years ago for his pet dog was listed under “possible relatives”, likely because it shared his last name and address11. This tells us that people search engines, like humans, can make mistakes. Given that they process data on a scale of billions, achieving absolute accuracy seems impossible. We can’t help wondering: how do they handle these inevitable errors?
Balancing efficiency and accuracy
Building a people search engine involves a crucial trade-off: efficiency versus accuracy. Users want accurate results, but achieving 100% accuracy is practically impossible and not worth it. Imagine the effort required to filter out inconsistent data formats or distinguish between people with the same name manually. This level of accuracy would be incredibly time-consuming and expensive, making the product too costly for most people.
Besides, even with advancements in data-matching technology, inaccuracies are still inevitable. The current matching techniques rely heavily on text matching, which might lead to duplicate records in reports, especially when the data formats are inconsistent. For example, an individual’s name might be spelled differently across various sources (such as “Mike” and “Michael”), so the same person may end up with multiple entries as the system may treat them as separate persons. Correcting these inaccuracies requires huge extra efforts and will eventually drive up the cost.
In general, people search engines will strike a balance by prioritizing efficiency and information richness over absolute accuracy. They aim to quickly provide users with as much relevant information as possible, even if it’s not perfectly accurate. This way, users can review and verify the results themselves and make informed decisions about the information. The guiding philosophy is: “Give me the data, and I’ll decide”.
Ultimately, people search engines provide a powerful tool for finding the information that’s most extensive and relevant, even if it requires a bit of extra scrutiny on your part. For users who want prompt results without spending much time and effort, this approach is invaluable.
The bottom line
In this article, we embarked on a journey to explore some of the technical secrets behind people search engines. At their core, people search engines use a sophisticated system to collect, process, and match data, before compiling them into personal profiles. They access information from a wide range of sources and use advanced data-matching algorithms to connect the dots. And this technology can help reveal the real identities behind virtual personas and recognize familial relationships.
While inaccuracies are inevitable, people search engines provide undeniable value to their users. Their focus on gathering extensive information helps users find individuals even with just a few details. And their automated data-matching quickly processes vast amounts of data, delivering fast and helpful results. This is definitely a game-changer for people who need as much relevant information as possible right away. As data processing and matching technologies continue to evolve, we can expect more reliable results from people search engines. Whenever you’re connecting with an old friend or learning more about a person, people search engines have the expertise and resources to help you on your journey.
References
- Statista. (2024, April). Global internet penetration rate as of April 2024, by region. Statista. https://www.statista.com/statistics/269329/penetration-rate-of-the-internet-by-region/[↩]
- Robertson, Adi. (2017, March 27). The long, weird history of companies that put your life online – And their tough, confusing path forward. The Verge. https://www.theverge.com/2017/3/21/14945884/people-search-sites-history-privacy-regulation[↩]
- Social Catfish. (2024, June 4). How To Know It’s Time For An In-Depth Search Specialist. https://socialcatfish.com/scamfish/how-to-know-its-time-for-an-in-depth-search-specialist/[↩]
- Cox, Joseph. (2019, September 6). DMVs Are Selling Your Data to Private Investigators. VICE Magazine. https://www.vice.com/en/article/43kxzq/dmvs-selling-data-private-investigators-making-millions-of-dollars[↩]
- Federal Trade Commission. (2014, May). Data Brokers – A Call for Transparency and Accountability. https://www.ftc.gov/system/files/documents/reports/data-brokers-call-transparency-accountability-report-federal-trade-commission-may-2014/140527databrokerreport.pdf[↩][↩]
- Leetaru, Kalev. (2018, December 15). What Does It Mean For Social Media Platforms To “Sell” Our Data? Forbes. https://www.forbes.com/sites/kalevleetaru/2018/12/15/what-does-it-mean-for-social-media-platforms-to-sell-our-data/[↩]
- https://brightdata.com/lp/web-data/datasets#social-media[↩]
- Ravichandran, Hari. (2024, March 1). How To Remove Yourself From Data Broker Sites. Aura. https://www.aura.com/learn/how-to-remove-yourself-from-data-broker-sites[↩]
- Hussey, Michael. P. JR. & Baranov, Pavel. A. et al. (2009). Distributed personal information aggregator. (U.S. Patent No.10242104). Retrieved from https://patents.google.com/patent/US10242104B2/en?q=(peekyou)&oq=peekyou[↩]
- Jain, Naveen. k. & Arnold John. K. et al. (2005). Household grouping based on public records. (U.S. Patent No.8938434). Retrived from https://patents.google.com/patent/US8938434B2/en?q=(intelius)&oq=intelius[↩]
- r/privacy [Photononic]. (2022, July 12). In my experience they go by surnames only. I do not appear very many places, but my brother is a… [Comment on the online forum post How do data mining companies know who your relatives are?]. Reddit. https://www.reddit.com/r/privacy/comments/vx0tey/how_do_data_mining_companies_know_who_your/[↩]





